

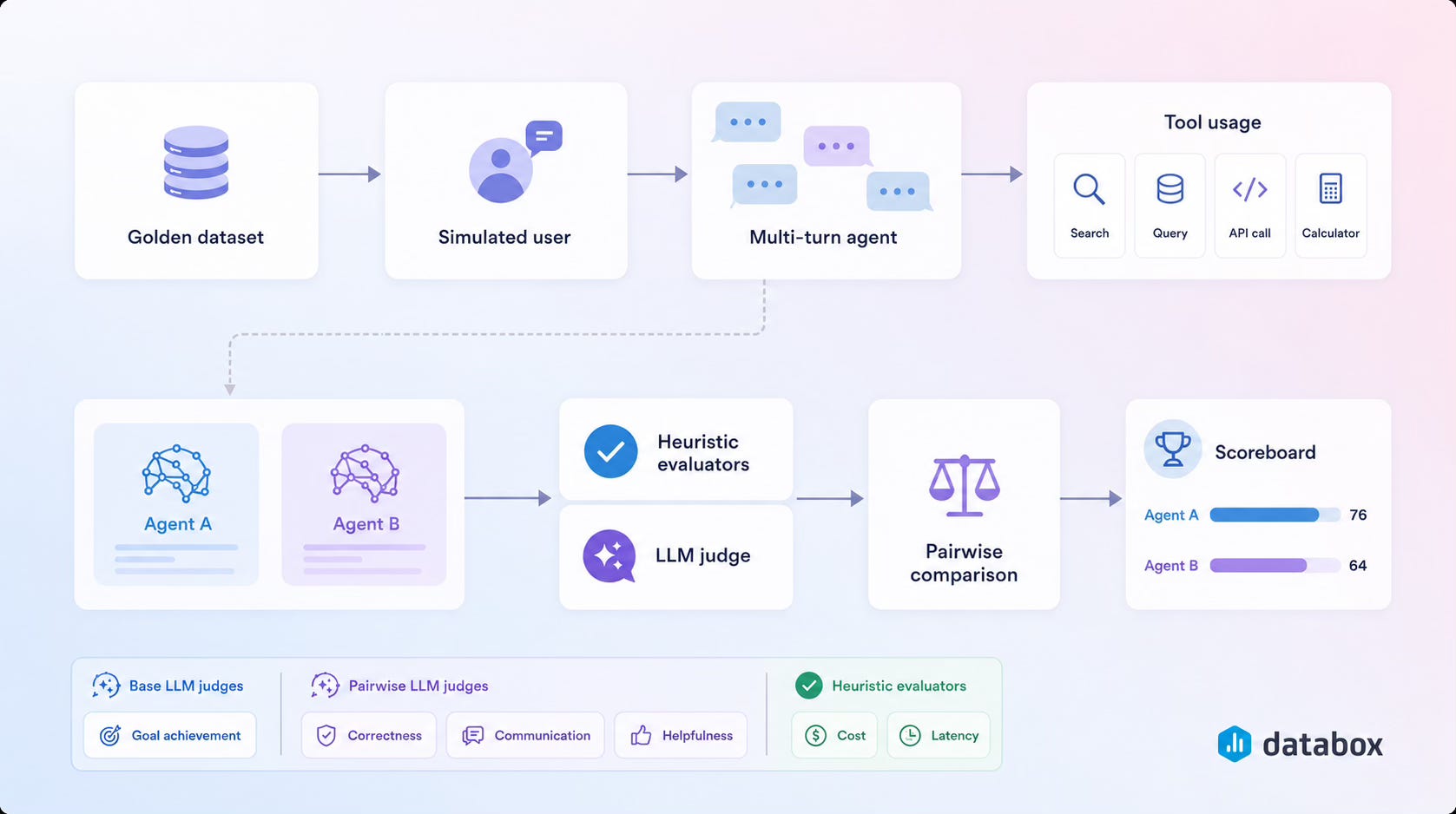
How we evaluate a multi-turn agent at Databox
Running evals is one thing. Building evals reliable enough to act on is another.

The methodology for agent evals is not settled. The work takes time, and other product features always seem more urgent. But without it, you are flying blind every time you make a change.
When we started building evals for Genie, our analyst agent, we wanted to answer one question. When we change the model, swap the prompt, or refactor the architecture, are we improving the agent, or regressing it?
We use a curated golden dataset in a sandbox account, driven by a goal-aware simulated user, and scored by a mix of heuristic, LLM-as-judge, and pairwise evaluators.
The golden dataset
Our golden dataset is relatively small. Examples are LLM-drafted, but each one earns its place through review. For the dataset to do its job, it has to satisfy three properties.
Sandbox-compatible: The dataset lives in a real but isolated Databox account. The agent creates real metrics, databoards, and artifacts. The only difference from production is that nobody depends on that workspace.
Because everything is real, the examples have to be tailored to the connected sources and setup on the account. If we need an example to work, we shape the account to match: connecting additional sources, configuring metrics, whatever the example requires. The inverse also holds. Some user requests are impossible to fulfill given the account’s setup, and we keep a handful of those in the dataset on purpose, to see how the agent handles them.
Representative of production: Shape and content mirror what real users actually ask, not toy questions written to make the agent look good. We monitor alignment between the golden dataset and production traces over time, so it does not silently drift away from what users are doing.
Documentation of capabilities: The dataset is a curated record of what Genie can do, not a statistical sample of all possible conversations. We expand it when we ship a new tool, add a capability, or discover a use case worth testing.
The simulated user
What drives the conversation in each example is not a recording but another LLM. We use openevals.create_llm_simulated_user for this.
The simulator pulls its instructions from the example row and drives the conversation turn by turn, up to a per-row turn budget. We estimate the budget based on how many turns we think the agent should reasonably need to complete the task. An agent that exhausts its budget by asking for things it could have figured out on its own pays for that in the score. The turn count becomes part of how we measure autonomy, on top of whether the agent achieved the goal at all.
Each example is a configuration along several axes, not just a prompt and an expected answer.
Mode is the type of task. Direct tasks should be resolvable in a single turn. The agent looks something up and returns the answer. Exploratory tasks are the research and reporting kinds where higher-reasoning models earn their cost, with the agent structuring a multi-step exploration and offering to go deeper. Ambiguous tasks are deliberately set up so the agent cannot complete reliably without consulting the user. A request to update a databoard, when several in the account share similar names. This is where we see whether the agent leans cautious or autonomous.
Style is how the user talks. Casual users speak in everyday language, use vague descriptions, and will use the wrong product terminology without noticing. The agent has to work just as well for users who aren’t perfectly familiar with the product’s vocabulary. Informed users speak the product’s language but are happy to let the agent lead. When the agent proposes an approach, they go with it rather than pushing back. This is the median user we expect to see in production. Technical users come in with a specific outcome in mind and steer the agent toward it, almost impatiently. They specify exact metric names, date ranges, and chart types upfront, and correct course the moment the agent strays. Where the informed user is happy to be guided, the technical user does the guiding.
Active entities is the UI context the user brings into the conversation. For datasets, databoards and performance insights, the view the user launched Genie from gets attached automatically. Data sources can also be attached directly through the chat input. The agent should use whichever context is active by default, without being told. Two examples can share the same initial message (Show me GA4 sessions as a line chart for the last 30 days) but differ in active_entities. With a GA4 connection active, the agent should pull data without asking. With nothing active, it should ask which connection to use, because we have more than one. Same prompt, different state. The column tells us whether the agent reads the room.
Required tools is the column we use for direct tasks where one specific tool call is clearly right. A direct visualization request should invoke a metric visualization tool. These examples act more like unit tests than agent evals, with a narrow, mostly binary signal (did the agent call the expected tool?). We leave the column empty for exploratory and ambiguous tasks, which have multiple valid solution paths.
Each example is a point in a space of design choices: mode, user style, active entities, required tools, initial message, max turns.
What we score
Each run of the dataset produces a score per example, per evaluator. LangSmith supports two kinds of experiments: base experiments, which run the agent against the dataset, and pairwise experiments, which compare two base experiments on the same dataset and score them against each other. We use both. The evaluators that run on each are different.
Heuristic evaluators compute scores directly from the conversation trace, with no model calls of their own. Cost in dollars (derived from token counts and the model’s pricing), latency, token counts themselves. They are cheap and fast, but they only measure what is mechanically observable. They cannot tell you whether the answer was correct. We use them for observability on each run, and to compare cost and latency against a baseline in pairwise experiments.
Base-experiment LLM evaluators send the conversation to a separate LLM and ask it to score against a structured rubric. The one we most often use is goal_achievement. It scores each example against its user_goal and success_criteria. Combined with the turn count, it signals both effectiveness (was the goal met?) and efficiency (was it met within the budgeted turns?).
Pairwise LLM evaluators take two base experiments and produce a winner per example. We have three, deliberately chosen to be non-overlapping:
pairwise_correctnessjudges what the agent did (scored against tool usage, data accuracy, and behavior compliance). It sees tool calls and the internal reasoning.pairwise_communicationjudges how the agent talked. Tone, clarity, the structure of the response. The user-facing surface.pairwise_helpfulnessjudges whether the user actually got what they needed. Outcome rather than process.
The three carve the response into three non-overlapping surfaces: action, presentation, outcome. An agent can do the wrong thing politely, the right thing rudely, or the right thing without actually helping. The three evaluators keep these failure modes separate rather than averaging them into a single ambiguous verdict.
pairwise_correctness has one design choice worth flagging on its own. Its system prompt and the analyst agent’s system prompt share the same behavioral rules. The evaluator knows what the agent was told to do, and its job is to score whether the agent actually did it.
Some of today’s rules:
Act when you can, ask when you must.
Resolve ambiguity through tools before asking the user.
Verify before creating. Check whether a metric already exists before creating a new one.
A generic LLM evaluator drifts toward generic helpfulness. It rewards politeness and under-penalises wrong tool choice. Asked to compare two conversations without any product context, it will tend to pick the one that sounds more articulate over the one that did the right thing. Giving the evaluator the agent’s own rules grounds the verdict in your contract, not in what the model’s training data happened to reward.
What we trust
Even with grounded evaluators, individual scores are not what we make production decisions on.
Absolute scores are unreliable. The numeric score (0 to 1) drifts based on the evaluator’s mood, the model’s current temperament, and a dozen other things that have nothing to do with the agent. Label-based outputs (Excellent, Good, Fair, Poor from conversation_quality, or yes, partial, no from goal_achievement) are more stable, but most runs land somewhere in the middle of the label range and the absolute verdict on a single example tells us very little.
What we use for decisions is pairwise comparison against a baseline: the prompt and model setup currently deployed in production. When we change a prompt, swap a model, or refactor the architecture, we run the new setup as a pairwise against the baseline. Each example produces a win, a loss, or a tie. The tie matters. Forcing the evaluator to pick a winner on every example would manufacture signal where there is none.
We do not watch a specific win-rate threshold. We read the per-example verdicts, spot-check the reasoning the evaluator attached to each, and form a qualitative read on whether the new setup is genuinely better. The same win-rate can mean very different things: a pairwise where most wins are both were fine, but B handled the chart format slightly better is a different signal than a pairwise where the wins are A made a real error that B avoided. The number is the entry point. The reasoning is what we actually read.
When a single evaluator returns its lowest label, we do not treat that as the agent failing. We open the trace in LangSmith and look at what actually happened. Sometimes it is an agent bug worth fixing. More often it is the example itself that needs work: a vague success criterion, an unrealistic max_turns budget, an active_entities setup that does not actually exercise the capability we thought it did. The dataset is a living document. Low scores are as much a signal about the dataset as about the agent.
One application worth flagging: we have two baselines, not one. Genie has a configurable thinking effort, with standard and extended modes backed by different prompts on LangSmith Hub. Extended has to win pairwise against standard by a noticeable margin to justify its existence as a separate mode, given the cost and latency it carries.
Case study
About a week before Genie shipped, the architecture rewrite was done. We had moved to LangSmith’s deep agents framework. The architect flagged one caveat that would matter later: deep agents work much better with Anthropic than with OpenAI models, because Anthropic models follow skills much more reliably whereas OpenAI models tend to ignore them. The improvement over the old framework was orders of magnitude. The baseline was obliterated, we did not need evals to tell us that.
What we did need evals for, with a week to launch, was the cost and latency calibration on the two modes. The plan going in was Sonnet at default effort for standard mode, Sonnet at max effort for extended mode. We ran the pairwise and found that max effort produced more tokens without producing better output. That changed the plan: standard moved to Haiku, extended stayed on default-effort Sonnet.
A week or two after launch, Anthropic had a few outages and we started thinking about fallbacks. I ran pairwise evaluations comparing Sonnet against GPT 5.3 chat and GPT 5.3 codex. Both GPT models won. Not narrowly. By a lot, across most examples, with about half the latency and about a sixth of the cost. That set off my alarm. If the GPT models genuinely outperformed Sonnet, we should not be defaulting to Sonnet. I prepared to make the case to stakeholders that we should switch.
The internal feeling, though, was that everyone loved how Sonnet worked. But because stakeholders had a hard time putting into words what made Sonnet’s outputs better, I wanted to confirm whether the preference held up. To check, I prepared a blind experiment in which I randomized the run order, and asked stakeholders to vote on which thread they preferred without knowing which model produced it. Sonnet won the blind test. Clearly enough that there was no question.
The disconnect was with the evaluators, not Sonnet versus GPT. The pairwise evaluators had told us GPT was better. The humans, in a blind comparison, said Sonnet was better. The evaluators were measuring something other than what we actually valued.
The fix was to update the evaluators to better match the system prompt and to force ourselves to clearly define what we wanted the agent to do. What I had read as a sign of bias was actually the spec process surfacing. This is also where the discipline boundary lives. It is fine to update evaluators to make good more precise. It is not fine to update evaluators to favor whichever model you already wanted to win. The difference between those two things is whether you are clarifying the contract or rigging the verdict.
Challenges
Production-trace replay does not work. The first thing you would try is to take recorded conversations, run the agent again on the same inputs, and score the differences. For a multi-turn agent that mutates real state, it fails two ways. Live replay runs the agent against the original production accounts and creates real metrics, real databoards, real changes to customer data. Whatever the scoring tells you, the cost of getting there is unacceptable. Mocked replay breaks because turn three’s user message depends on what the agent actually produced at turn two. Replace the tool outputs with mocks and the conversation drifts within one or two turns. The simulated user is replying to a different reality than the one in the recorded thread. The replay has stopped being a replay.
Encoding behavior in plain English is its own discipline. Writing rules concisely, without redundancy, without rules that contradict each other under specific conditions, takes more iteration than you would guess. The rules also do not transfer cleanly between model providers, or even between model versions. The same prompt that produces measured, deliberate behavior on Sonnet produces a different personality on GPT, and Sonnet itself has shifted behavior across versions. Our current solution is a set of universal core rules that hold across providers, plus a model-specific extension layer for each model’s quirks.
It is easy to get the evals to confirm what you want to hear. Evaluators are not measuring objective truth. They are measuring what we told them to measure. If we want a model to win and we phrase the success criteria the right way, the evaluators will tell us the model wins. The case study above is the worked example: we caught ourselves about to ship a wrong default because the evaluators were grading on something other than what we actually valued. The blind test was the safety net.
Who owns this work? Right now it is a PM and an AI engineer collaborating, which is a small crew for a discipline that touches product behavior, technical implementation, and shipping decisions. The natural direction is for more of it to move toward domain experts as the infrastructure matures, but right now the eval setup is small and centralized enough that two people can hold the whole picture. That is not going to scale forever.
What comes next
Our near-term priority is making evals easier to run by people who are not engineers. Today, anyone running an experiment needs the right repo, environment, and credentials. That is fine when the work is owned by one or two engineers. It does not scale to stakeholders.
The next piece of infrastructure is an eval service that accepts an experiment specification via HTTP and CLI and runs it asynchronously on shared hardware. Once that exists, anyone with HTTP access becomes a consumer: GitHub Actions on PRs that touch agent code, a Slack slash command for PMs, scheduled runs that catch silent drift in the upstream model provider, agentic workflows that submit experiments without a human in the loop.
The bigger picture is that we do not think the eval question is closed. Agent evaluation is still an open problem in the field. We have a setup that catches enough today to move forward, and an honest list of what it does not catch yet.
Some of those gaps will close by extending what is here. The dataset will grow with the agent. The evaluators will get tuned as we learn more about what we actually value. The evaluator prompts will track product changes. None of that requires a redesign.
Some of the gaps will need a different shape. As more agents get added to the system, each will likely need its own evaluators, its own simulated user, its own success-criteria contract. What worked for the analyst may not generalise to the next one. The eval service will help us scale the running of evals, but the designing of evals stays a per-agent discipline.